Sia
X1, X2,…, Xnun campione
aleatorio tratto da una popolazione che ipotizziamo avere una
distribuzione determinata, con uno o più parametri incogniti. Si
pone naturalmente il problema: a partire dai dati
Xi, quale è il valore del/dei parametri incogniti
che è più plausibile (dal punto di vista probabilistico) ipotizzare?
Due sono le modalità di approccio: con il metodo degli stimatori
puntuali della massima verosimiglianza o con la stima degli
intervalli di confidenza.
Stima di massima
verosimiglianza
La probabilità o la densità di probabilità
congiunta del presentarsi dei valori
Xi nel campione è una funzione f dei valori stessi
condizionati dal parametro o dai parametri incogniti
θi. Abbiamo cioè:
22) P = f(x1, x2,…,xn/θ1,…,
θm)
La f
è detta funzione di verosimiglianza o di “likelihood” in lingua
inglese.
Si assume, come appare plausibile, che i valori
incogniti
θi siano quelli che rendono massima la funzione
f, o, che è lo stesso,
il logaritmo di f, cosa
che talora agevola il calcolo. Se i valori del campione sono
indipendenti la probabilità congiunta
P (e quindi
f) è il prodotto delle
singole probabilità e dall’analisi matematica sappiamo che i valori
delle variabili
θi che massimizzano una funzione sono da
ricercarsi tra quelli che annullano le derivati parziali prime.
Ipotizziamo per fare un esempio molto istruttivo
che le
Xi indipendenti siano dedotte da una popolazione
di variabili aleatorie normali di media μ e deviazione standard σ
incognite.
La funzione
f sarà:
moltiplicando i fattori e calcolando il logaritmo
abbiamo:
Le derivate parziali di tale logaritmo sono:
Ponendole = 0 si ottiene il sistema a due
incognite
μ e
σ
che da per
μ e
σ le stime:
e le statistiche o stimatori di massima
verosimiglianza per μ e σ sono risp.
La media dello stimatore per
non
da tuttavia, come abbiamo visto prima
σ2 ma
(n-1)/n σ2.
Esso viene chiamato stimatore distorto , “biased
estimator” in inglese.
Intervalli di
confidenza
Sia abbia una statistica campionaria
f(
Xi …
Xn)
di una popolazione di cui non sono noti alcuni parametri
caratteristici quali ad es. la media μ o lo scarto quadratico medio
σ. La statistica è una variabile aleatoria come le variabili che la
caratterizzano ed avrà perciò una sua distribuzione. A partire da
essa si può, invece che determinare una stima puntuale dei parametri
incogniti della popolazione, stimare degli intervalli numerici
all’interno dei quali si può collocare con un certo grado di
probabilità o, più precisamente, di confidenza il valore del
parametro ricercato.
Fig.7 - Densità t di Student
Sia data ad esempio una popolazione normale di media
μ
incognita e varianza
σ2 nota di cui si abbia un campione
Xi la cui media campionaria sia
.
Sappiamo che la variabile
ha media
μ e scarto quadratico medio σ/√n. Ne
consegue che la variabile standardizzata:
(
- μ)/ σ/√n è normale
standard cioè ~ N (0,1).
Dalle tavole di ripartizione della normale abbiamo ad esempio:
Che diventa:
Ottenuto dal campione il valore
per la media
, con il 95 % di confidenza
la media μ della popolazione giace nell’intervallo indicato con
=
.
Intervallo di
confidenza per la media di una distribuzione normale con varianza
non nota.
Se per una popolazione normale la varianza non è
nota, utilizzando la varianza campionaria.
costruiamo
la variabile
la quale per quanto visto sopra è una variabile “t”
di Student con n-1
gradi di libertà. La sua distribuzione, simmetrica rispetto a 0, è
tabellata.
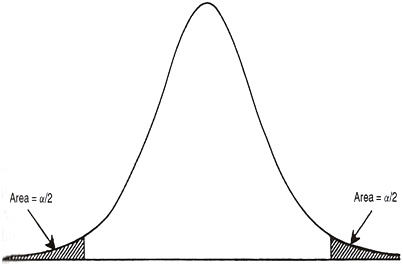
Indicando con
1- α la confidenza
desiderata, con tα/2,n-1
il valore di T la cui
probabilità di superamento è pari ad
α/2, abbiamo:
Rilevati dal campione
=
ed S = s con
probabilità pari 1- α
l’intervallo corrispondente alla 25) contiene il valore di
μ.
Intervalli di
confidenza per la varianza di una distribuzione normale
La statistica
(n-1)S2/σ2,
dove
è
la varianza campionaria, che come abbiamo visto ha una distribuzione
chi-quadro con n-1 gradi di libertà, cioè:
(n-1)S2/σ2
~ X2n-1
Da questo possiamo dedurre che se desideriamo
determinare un intervallo di confidenza =
1-α
per
σ2
abbiamo:
Determinato
S = s
l’intervallo ad una confidenza pari a
1-α
é:
Intervallo di
confidenza per la differenza tra le medie di due popolazioni normali
Se
Xi
ed
Yi
sono due campioni di popolazioni normali di medie
μ1ed
μ2 e varianze
σ1
e
σ2 rispettivamente, le medie di
X e
Y
saranno
μ1
ed
μ2
e le varianze σ12/n
e σ22/n . La
differenza delle medie
-
̅
sarà ancora una variabile normale con media
μ1 - μ2 e varianza
σ12/n
+ σ22/n (la media di una somma è = alla
somma delle medie e la varianza della differenza di due variabili
indipendenti è ancora = alla somma delle varianze, giacché
x-y = x+(-y) e Var (–y) = Var
[ (-1)y)]= (-1)2 Var (y)) = Var (y))
Gli intervalli di confidenza si determinano come
per la variabile normale.
Se le
σ1
e
σ2 non sono noti ma uguali, l’intervallo di confidenza
è fornito dalla distribuzione” t di Student e si ha ipotizzando che
le varianze incognite siano uguali:
Dove
Sp
ha l’espressione:
Test di
significatività
Si abbia una statistica di un campione tratto da
una popolazione di cui non conosciamo uno o più parametri quali ad
esempio la media μ o la
varianza σ2.
Può accadere che si debbano fare delle ipotesi su tali parametri,
ipotesi che possono essere vere od errate. Si chiamano ipotesi
nulle, H0, le ipotesi
da confermarsi a partire dai dati del campione, ipotesi alternative,
H1 le ipotesi
differenti di quelle nulle.
Se, in funzione dei dati del campione, rifiutiamo
l’ipotesi H0 che in
realtà è vera e dovrebbe essere accettata, commettiamo un errore di
tipo I. Se al contrario
accettiamo l’ipotesi H0
che dovrebbe in realtà essere rifiutata, commettiamo un errore di
tipo II.
Stime dei valori
medi
Si dia un campione di una popolazione di cui sia
noto lo scarto quadratico medio o deviazione standard
σ ed il cui valore
medio sia
.
Si faccia l’ipotesi H0
che la media della popolazione sia o possa essere attorno ad
μ0 e ciò
comunque non sia in contraddizione con i dati campionari, a fronte
dell’alternativa H1 che
sia μ , maggiore,
minore o comunque di versa da
μ0. L’ipotesi
H0 non sia del tutto
casuale ma confortata da alcuni elementi di merito così che
imponiamo che il rischio di rifiutare
H0 anche se vera,
commettendo un errore di tipo
I, sia basso o molto basso. Fissando ad esempio delle
probabilità del 5% o dell’1%, rifiuteremo l’ipotesi
H0 al “livello di
significatività” di 0,05 o 0,01 se la media
cadrà a una distanza abbastanza grande da
μ0.
Se la popolazione è normale o sufficientemente numerosa, la media
campionaria
di media μ0
avrà varianza σ2/n
sicché la corrispondente variabile standardizzata
una gaussiana standard
Avremo che accetteremo l’ipotesi nulla
H0 indicando con α il
livello di significatività se:
A fronte di
H1 μ
> μ0
A fronte di
H1 μ
< μ0
A fronte di
H1 μ
μ0
Dove zα
è tale che la probabilità che la variabile normale standardizzata
Z sia maggiore di
zα è
α. Analogalmente per
zα/2
Fig. 8 - Area di rigetto dell’ipotesi nulla:H0
μ
= μ0 a fronte di H1
μ0
La probabilità che la variabile normale standard
Z sia maggiore del
valore standardizzato del campione
o “statistica del test” è chiamata probabilità p – dei dati.
Qualora la varianza della popolazione non sia
nota, la si può sostituir con la varianza campionaria:
In tale contesto la variabile aleatoria
ha la distribuzione “t”
di Student con n-1
gradi di libertà. Valutazioni relative alle ipotesi
H0 ed
H1 si porteranno avanti
come visto sopra considerando la variabile
ed utilizzando le curve e le tabelle relative alla distribuzione di
questa variabile.
Verifica se due
popolazioni hanno la stessa media
Dati due campioni indipendenti
X1, X2,…,
Xn e Y1,Y2,…,Ym
di due popolazioni normali aventi medie
μx e
μy e
varianze σx
e σy, si
voglia verificare la plausibilità dell’ipotesi
H0, che le medie delle
due popolazioni siano uguali:
μx = μy cioè che
μx - μy
= 0 a fronte dell’ipotesi
H1, che
μx
μy.
Consideriamo la differenza delle due medie
campionarie,
-
,
che ha media μx - μy
e varianza , tale
distribuzione è ancora normale per cui si ha:
,
tale distribuzione è ancora normale per cui si ha:
cioè è normale standard.
La statistica, se l’ipotesi
H0 è vera,
diventa:
e si rifiuterà o accetterà H0
Cioè se il valore assoluto di
è > oppure ≤ di zα/2
Se le varianze delle popolazioni non sono note ma
uguali , si calcoleranno le varianze campionarie
e la varianza mediata
La statistica del test
avrà la distribuzione “t”
di Student con n+m-2
gradi di libertà.
Si rifiuterà
Ho =
(μx = μy ) se il valore
assoluto di
T è > tα/2,n+m-2si accetterà in caso contrario, dove come sopra
tα/2,n+m-2
è il valore della variabile t che ha la probabilità di
essere superata pari ad
α/2sulla curva di Student standardizzata a
n+m-2
gradi di libertà, essendo α
il valore di significatività prescelto.
Verifica di ipotesi
sulla varianza di popolazioni normali
Sia data l’ipotesi
H0
che la varianza di una popolazione normale sia
σ0
a fronte dell’ipotesi
H1
che sia σ
σ0 .
Da quanto visto precedentemente la variabile
(n-1)S2/ σ2ha una distribuzione chi-quadro con
n-1gradi di libertà. Abbiamo cioè:
Se H0
è vera
σ2 = σ02
e sarà:
Si accetterà
H0
con livello di significatività
α
se:
Si rifiuterà
H0
in caso contrario
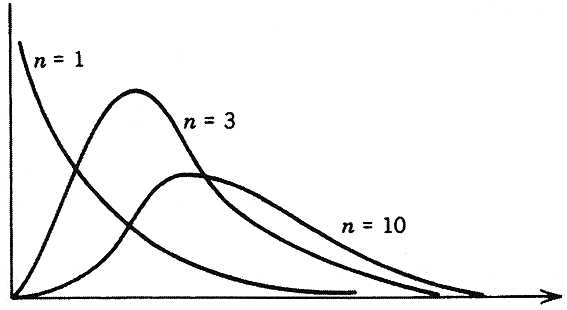
Fig.9 - Funzione chi-quadro per alcuni gradi di
libertà
Verifica di ipotesi
sulla differente varianza di due popolazioni normali
Siano dati due campioni di due popolazioni
normali indipendenti
X1,…,
Xn e Y1,…, Ym
di varianza
σx2
e σy2.
Si debba verificare l’ipotesi
H0
: σx2 = σy2contro
σx2 σy2.
Definite come sopra le due varianze campionarie
e (n-1)
sono due chi-quadro con
n-1ed
m-1gradi di libertà risp. Il loro rapporto ha una distribuzione
F
di Fisher con parametri
n-1
e
m-1, e se
H0è vera si ha:
E si accetterà
H0
con grado di significatività αse:
Avendo indicato con
Fα/2,n-1,m-1
oF1-α/2,n-1,m-1il valore della variabile
F
il cui depassamento ha una probabilità pari ad
α/2
o ad
1-α/2
sulla curva della distribuzione di
F.